This guide provides a curated list of common Apache Hive interview questions to help you prepare for your next Data Engineer or Big Data Developer role. Master these concepts to demonstrate your expertise in data warehousing and large-scale data analysis.
Last Updated: Aug 30, 2025
Table of Contents
Core Concepts & Architecture
1. What is Apache Hive?
Apache Hive is a data warehouse system built on top of Apache Hadoop for providing data query and analysis. It gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. Hive converts SQL-like queries into MapReduce or Tez jobs. You can learn more from the official Apache Hive website.
2. What is the difference between Hive and a traditional RDBMS?
- Schema: Hive uses schema-on-read, meaning the schema is applied to the data when it's read. RDBMS uses schema-on-write, where the schema is enforced when data is written.
- Workload: Hive is designed for batch processing and large-scale analytics (OLAP), not for real-time transactional queries (OLTP).
- Updates: Hive does not support row-level updates and deletes in the same way as an RDBMS (though it has some support via ACID transactions).
- Data Storage: Hive stores data in a distributed file system like HDFS, while RDBMS typically uses its own optimized storage format.
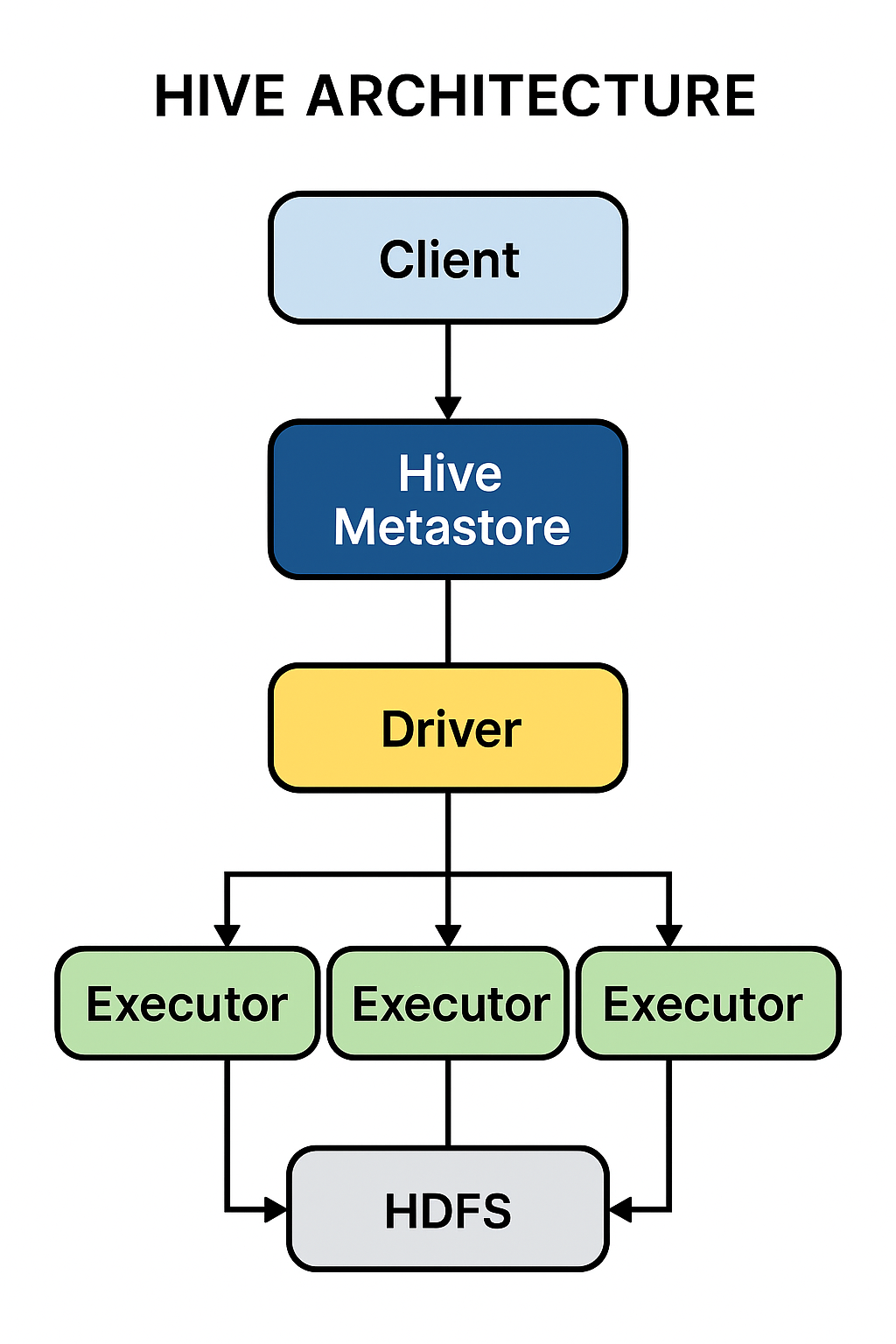
3. What are the main components of the Hive architecture?
The main components are:
- Metastore: Stores the metadata for Hive tables, such as their schema and location.
- Driver: Manages the lifecycle of a HiveQL query as it moves through Hive.
- Compiler: Compiles the HiveQL query into a directed acyclic graph (DAG) of MapReduce or Tez jobs.
- Optimizer: Performs various transformations on the execution plan to optimize it.
- Execution Engine: Executes the compiled jobs in the correct order on Hadoop.
4. What is the Hive Metastore?
The Hive Metastore is a central repository that stores all the metadata about Hive tables, partitions, schemas, and locations. It can be configured in different modes (embedded, local, or remote) and typically uses a relational database like MySQL or PostgreSQL for storage.
5. What are the different modes of Hive Metastore?
- Embedded Mode: Metastore runs in the same JVM as Hive and uses an embedded Derby database (suitable for testing only).
- Local Mode: Metastore runs in the same host as Hive but uses a separate database like MySQL.
- Remote Mode: Metastore runs on a separate server and can be accessed by multiple Hive instances.
6. What is HiveQL?
HiveQL (HQL) is Hive's query language similar to SQL. It allows users to write queries that are similar to SQL but are converted into MapReduce, Tez, or Spark jobs for execution on Hadoop.
7. What are the different execution engines supported by Hive?
- MapReduce: The original execution engine (slowest)
- Tez: More efficient than MapReduce, uses directed acyclic graphs (DAGs)
- Spark: Uses Apache Spark for in-memory processing (fastest)
8. What is the difference between Hive and Pig?
- Hive: Uses SQL-like language (HQL), better for structured data and users familiar with SQL
- Pig: Uses Pig Latin scripting language, better for complex data pipelines and ETL processes
9. What is the difference between Hive and Impala?
- Hive: Batch processing, higher latency, more fault-tolerant
- Impala: Interactive queries, lower latency, less fault-tolerant
10. What are the limitations of Hive?
- High latency (not suitable for real-time queries)
- Limited support for row-level updates and deletes
- Not designed for OLTP workloads
- Sub-optimal for small datasets
Data Model: Tables, Partitions & Buckets
11. What are the different types of tables in Hive?
- Managed (Internal) Tables: Hive manages both the metadata and the data. Dropping the table deletes the data.
- External Tables: Hive only manages the metadata. Dropping the table doesn't delete the underlying data.
12. When would you use an external table vs a managed table?
- Use external tables when data is used by multiple tools or needs to persist after table deletion
- Use managed tables when Hive should have full control over the data lifecycle
13. What is partitioning in Hive?
Partitioning is a method to divide a table into related parts based on the values of particular columns (like date, country, etc.). Each partition corresponds to a specific value of the partition column and is stored as a subdirectory in the table's directory.
14. What are the benefits of partitioning?
- Faster query execution (partition pruning)
- Better data organization
- Easier data management
- Improved performance for range queries
15. What is bucketing in Hive?
Bucketing is a technique that decomposes data into more manageable parts (buckets) based on the hash function of a column in the table. Each bucket is stored as a file in the partition directory.
16. What are the benefits of bucketing?
- Faster joins (map-side joins)
- Efficient sampling
- Better performance for certain queries
- More balanced data distribution
17. What is the difference between partitioning and bucketing?
- Partitioning: Creates directories based on column values, good for filtering
- Bucketing: Creates files based on hash values, good for joins and sampling
18. What is dynamic partitioning in Hive?
Dynamic partitioning allows Hive to automatically create partitions based on the values of the partition columns in the inserted data. You don't need to specify each partition manually.
19. What is static partitioning in Hive?
Static partitioning requires you to explicitly specify the partition values when loading data into the table. You need to know the partition values in advance.
20. How do you enable dynamic partitioning in Hive?
Set the following properties:
SET hive.exec.dynamic.partition = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
21. What is a view in Hive?
A view is a virtual table based on the result set of a HiveQL query. It doesn't store data itself but provides a way to simplify complex queries or restrict access to certain data.
22. What is an index in Hive?
An index in Hive is a data structure that improves the speed of data retrieval operations on a table. Hive supports compact and bitmap indexes.
23. What are the different types of indexes in Hive?
- Compact Index: Stores the HDFS block IDs for each indexed value
- Bitmap Index: Uses bitmap vectors for columns with low cardinality
24. What is a transactional table in Hive?
Transactional tables (ACID tables) support atomicity, consistency, isolation, and durability. They allow operations like INSERT, UPDATE, and DELETE at row level.
25. How do you create a transactional table in Hive?
Use the TBLPROPERTIES clause:
CREATE TABLE table_name (...)
TBLPROPERTIES ('transactional'='true');
HiveQL: DDL, DML & Functions
26. What are the different data types supported by Hive?
- Primitive: TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, BOOLEAN, STRING, TIMESTAMP, etc.
- Complex: ARRAY, MAP, STRUCT, UNION
27. How do you load data into a Hive table?
Using the LOAD DATA statement:
LOAD DATA [LOCAL] INPATH 'file_path' [OVERWRITE] INTO TABLE table_name [PARTITION (part_col=val)];
28. What is the difference between LOAD DATA and INSERT in Hive?
- LOAD DATA: Moves or copies files into Hive's warehouse directory (faster)
- INSERT: Processes data through MapReduce/Tez/Spark (slower but more flexible)
29. How do you insert data into a Hive table?
Using INSERT statements:
INSERT INTO TABLE table_name [PARTITION (part_col=val)] SELECT ...;
INSERT OVERWRITE TABLE table_name [PARTITION (part_col=val)] SELECT ...;
30. What is the difference between INSERT INTO and INSERT OVERWRITE?
- INSERT INTO: Appends data to the table
- INSERT OVERWRITE: Replaces the existing data in the table or partition
31. How do you update data in a Hive table?
For transactional tables, use the UPDATE statement:
UPDATE table_name SET column = value [WHERE condition];
32. How do you delete data from a Hive table?
For transactional tables, use the DELETE statement:
DELETE FROM table_name [WHERE condition];
33. What are the different types of joins in Hive?
- INNER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- LEFT SEMI JOIN
- CROSS JOIN (Cartesian product)
34. What is a map join in Hive?
A map join is a type of join where a small table is loaded into memory and joined with the larger table without requiring a reduce phase. This can significantly improve performance.
35. How do you enable a map join in Hive?
Set the following property or use the MAPJOIN hint:
SET hive.auto.convert.join = true;
SELECT /*+ MAPJOIN(small_table) */ ... FROM large_table JOIN small_table ...;
36. What are user-defined functions (UDFs) in Hive?
UDFs allow users to extend HiveQL functionality by writing custom functions in Java. There are three types:
- UDF: Regular function (one row in, one row out)
- UDAF: Aggregate function (multiple rows in, one row out)
- UDTF: Table-generating function (one row in, multiple rows out)
37. What are the different types of built-in functions in Hive?
- Mathematical functions (ROUND, CEIL, FLOOR, etc.)
- String functions (CONCAT, SUBSTR, UPPER, LOWER, etc.)
- Date functions (YEAR, MONTH, DAY, DATEDIFF, etc.)
- Conditional functions (CASE, COALESCE, etc.)
- Aggregate functions (SUM, COUNT, AVG, MAX, MIN, etc.)
38. What is the ORDER BY clause in Hive?
ORDER BY performs a global sort of all data using a single reducer. It should be used with LIMIT to avoid performance issues with large datasets.
39. What is the SORT BY clause in Hive?
SORT BY sorts data within each reducer. It doesn't guarantee a global order but is more efficient than ORDER BY for large datasets.
40. What is the DISTRIBUTE BY clause in Hive?
DISTRIBUTE BY controls how map output is distributed to reducers. It ensures that all rows with the same values for the specified columns go to the same reducer.
41. What is the CLUSTER BY clause in Hive?
CLUSTER BY is a combination of DISTRIBUTE BY and SORT BY using the same columns. It distributes and sorts the data on the same set of columns.
42. How do you handle NULL values in Hive?
Hive treats NULL values as special values. You can use functions like:
- IS NULL / IS NOT NULL
- COALESCE (returns first non-NULL value)
- NVL (replaces NULL with specified value)
43. What is the difference between LIKE and RLIKE in Hive?
- LIKE: Simple pattern matching with % and _ wildcards
- RLIKE: Regular expression matching using Java regex patterns
44. What are lateral views in Hive?
Lateral views are used in conjunction with user-defined table generating functions (UDTFs) to explode complex data types like arrays or maps into multiple rows.
45. How do you use EXPLAIN in Hive?
The EXPLAIN command shows the execution plan for a query, which helps in understanding how Hive will execute it and identifying potential optimizations.
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query;
Data Storage & SerDe
46. What is SerDe in Hive?
SerDe stands for Serializer/Deserializer. It's an interface that tells Hive how to process a record. The Serializer converts Java objects to a format that Hive can write to HDFS, and the Deserializer converts the stored format back to Java objects.
47. What are the different file formats supported by Hive?
- TextFile (default)
- SequenceFile
- RCFile (Record Columnar File)
- ORC (Optimized Row Columnar)
- Parquet
- Avro
48. What is the difference between ORC and Parquet?
- ORC: Hive-native format, better compression, supports ACID transactions
- Parquet: More general-purpose, better for nested data, widely supported across Hadoop ecosystem
49. What are the advantages of using ORC format?
- Better compression
- Predicate pushdown
- Faster queries
- Support for ACID transactions
- Lightweight indexes
50. What are the advantages of using Parquet format?
- Columnar storage
- Efficient compression
- Predicate pushdown
- Good support for nested data
- Wide ecosystem support
51. What is compression in Hive and why is it important?
Compression reduces the size of data stored in HDFS, which saves storage space and improves query performance by reducing I/O. Common compression codecs include Snappy, Gzip, LZO, and Bzip2.
52. How do you enable compression in Hive?
Set the following properties:
SET hive.exec.compress.output = true;
SET mapreduce.output.fileoutputformat.compress = true;
SET mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
53. What is the difference between Snappy and Gzip compression?
- Snappy: Faster compression/decompression, lower compression ratio
- Gzip: Slower compression/decompression, higher compression ratio
54. What is a custom SerDe in Hive?
A custom SerDe allows you to define how Hive should serialize and deserialize data for specific formats not natively supported. You can write your own SerDe by implementing the SerDe interface.
55. How do you specify a file format when creating a table?
Use the STORED AS clause:
CREATE TABLE table_name (...)
STORED AS ORC; -- or PARQUET, SEQUENCEFILE, etc.
Performance Tuning & Optimization
56. What are some common techniques to optimize Hive queries?
- Partitioning and bucketing
- Using appropriate file formats (ORC, Parquet)
- Enabling compression
- Using vectorization
- Enabling Tez or Spark execution engine
- Using map joins for small tables
57. What is vectorization in Hive?
Vectorization allows Hive to process a batch of rows together instead of one row at a time, reducing CPU usage and improving performance. Enable it with:
SET hive.vectorized.execution.enabled = true;
58. What is predicate pushdown in Hive?
Predicate pushdown is an optimization technique where filtering is pushed down to the storage layer, reducing the amount of data that needs to be read and processed.
59. How do you control the number of mappers and reducers in Hive?
For mappers, it's controlled by the input format and file splitting. For reducers, use:
SET mapreduce.job.reduces = number;
Or let Hive automatically determine the number:
SET hive.exec.reducers.auto.enabled = true;
60. What is the significance of the hive.fetch.task.conversion property?
This property controls whether certain queries can be executed without MapReduce. When set to "more", simple queries like SELECT with LIMIT or filtering on partition columns can run faster without launching a MapReduce job.
61. How do you handle data skew in Hive?
- Use the SKEWED BY clause when creating tables
- Enable skew join optimization
- Use multiple reducers
- Manually handle skewed keys in queries
62. What is the purpose of the hive.optimize.skewjoin property?
When set to true, this property enables Hive to handle skew in join operations by creating separate jobs for skewed keys.
63. How do you optimize joins in Hive?
- Use map joins for small tables
- Place larger table last in the join order
- Use bucketing on join keys
- Enable parallel execution
64. What is the purpose of the hive.auto.convert.join property?
When set to true, this property allows Hive to automatically convert joins to map joins when appropriate, based on the size of the tables.
65. How do you optimize GROUP BY operations in Hive?
- Use the hive.map.aggr property to do partial aggregation in the map phase
- Use the hive.groupby.skewindata property to handle skew in grouping keys
- Ensure proper partitioning and bucketing
66. What is the purpose of the hive.groupby.skewindata property?
When set to true, this property enables Hive to handle skew in GROUP BY operations by launching an additional MapReduce job to distribute the data more evenly.
67. How do you optimize ORDER BY operations in Hive?
- Use LIMIT to reduce the amount of data sorted
- Consider using SORT BY instead if global ordering isn't required
- Increase the number of reducers for better parallelism
68. What is the purpose of the hive.exec.parallel property?
When set to true, this property allows Hive to execute independent stages of a query in parallel, which can improve performance for complex queries.
69. How do you handle small files in Hive?
- Use the hive.merge.mapfiles and hive.merge.mapredfiles properties to merge small files
- Use the hive.merge.size.per.task and hive.merge.smallfiles.avgsize properties to control merge thresholds
- Use appropriate partitioning and bucketing to avoid creating many small files
70. What is the purpose of the hive.exec.dynamic.partition.mode property?
This property controls the mode for dynamic partitioning:
- strict: Requires at least one static partition
- nonstrict: Allows fully dynamic partitioning
71. How do you monitor and analyze query performance in Hive?
- Use the EXPLAIN command to see the execution plan
- Check the Hive logs for detailed information
- Use Hadoop job tracker to monitor MapReduce jobs
- Use performance counters and metrics
72. What is the cost-based optimizer (CBO) in Hive?
The Cost-Based Optimizer uses table and column statistics to generate more efficient execution plans. Enable it with:
SET hive.cbo.enable = true;
73. How do you collect statistics in Hive?
Use the ANALYZE TABLE command:
ANALYZE TABLE table_name [PARTITION(part_col=val)] COMPUTE STATISTICS [FOR COLUMNS];
74. What is the LLAP (Live Long and Process) feature in Hive?
LLAP is a daemon that runs on worker nodes to provide caching, pre-fetching, and query fragment execution. It enables faster interactive queries by keeping data in memory.
75. How do you enable Tez as the execution engine in Hive?
Set the following property:
SET hive.execution.engine = tez;
Security & Integration
76. What are the different authentication methods in Hive?
- LDAP authentication
- Kerberos authentication
- Custom authentication plugins
77. What are the different authorization methods in Hive?
- Storage-based authorization (HDFS permissions)
- SQL standards-based authorization
- Apache Ranger integration
- Apache Sentry integration
78. How do you enable security in Hive?
Set the following properties:
SET hive.security.authorization.enabled = true;
SET hive.security.authorization.manager = org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory;
79. What is the difference between Hive and HBase?
- Hive: Data warehouse for batch processing, SQL-like queries
- HBase: NoSQL database for real-time read/write access, key-value storage
80. How do you integrate Hive with HBase?
Create an external Hive table that maps to an HBase table:
CREATE EXTERNAL TABLE hive_table(key string, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf:val")
TBLPROPERTIES ("hbase.table.name" = "hbase_table");
81. How do you integrate Hive with Amazon S3?
Use the s3a:// protocol in the table location:
CREATE EXTERNAL TABLE table_name (...)
LOCATION 's3a://bucket-name/path/';
82. How do you integrate Hive with JDBC-compliant databases?
Use the StorageHandler for the specific database or create an external table using the JDBC storage handler.
83. What is the Hive metastore service?
The Hive metastore service is a Thrift service that provides metadata access to Hive and other tools. It can be run in embedded, local, or remote mode.
84. How do you connect to Hive from other applications?
Use the Hive JDBC or ODBC drivers to connect from applications like Tableau, Excel, or custom Java applications.
85. What is the Hive Web Interface (HWI)?
The Hive Web Interface is a simple web-based GUI for running Hive queries and managing Hive tables. It's being deprecated in favor of more modern tools like Hue and Apache Zeppelin.
Advanced Topics & Ecosystem
86. What is Apache Tez?
Apache Tez is a framework for building high-performance batch and interactive data processing applications on Hadoop. It's designed as a more efficient replacement for MapReduce and is the default execution engine for Hive in many distributions.
87. What is the difference between Hive on MapReduce and Hive on Tez?
- MapReduce: Slower, more disk I/O, separate jobs for each stage
- Tez: Faster, less disk I/O, optimized execution plan with DAG
88. What is HiveServer2?
HiveServer2 is an improved version of HiveServer that supports multi-client concurrency and authentication. It provides a Thrift interface for clients to execute queries against Hive.
89. What is the difference between HiveServer and HiveServer2?
- HiveServer: Single-threaded, no authentication, deprecated
- HiveServer2: Multi-threaded, supports authentication, better security
90. What is Beeline in Hive?
Beeline is a command-line shell for HiveServer2 that uses JDBC to connect. It replaces the older Hive CLI (command line interface).
91. What is Apache Hue?
Apache Hue is a web interface for analyzing data with Apache Hadoop. It provides a SQL editor for Hive, making it easier to write and execute queries through a browser.
92. What is Apache Zeppelin?
Apache Zeppelin is a web-based notebook that enables interactive data analytics. It supports Hive and many other data processing systems through interpreter plugins.
93. What is the difference between Hive and Spark SQL?
- Hive: Batch processing, uses MapReduce/Tez, higher latency
- Spark SQL: In-memory processing, lower latency, better for iterative algorithms
94. What is Hive on Spark?
Hive on Spark allows Hive to use Apache Spark as its execution engine instead of MapReduce or Tez. This combines Hive's mature SQL capabilities with Spark's in-memory processing performance.
95. What is the future of Hive in the big data ecosystem?
Hive continues to evolve with features like LLAP for interactive queries, improved ACID support, and better integration with other technologies like Spark and cloud storage. While newer technologies like Spark SQL are gaining popularity, Hive remains important for batch processing and as a metastore service.
96. What are Hive streaming APIs?
Hive streaming APIs allow continuous ingestion of data into Hive tables. They are particularly useful for streaming data from systems like Kafka into Hive for near-real-time analytics.
97. What is the Hive ACID feature?
Hive ACID (Atomicity, Consistency, Isolation, Durability) provides transactional capabilities, allowing operations like INSERT, UPDATE, and DELETE at row level. This is implemented using ORC file format and a transaction manager.
98. How do you enable ACID transactions in Hive?
Set the following properties and use transactional tables:
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
SET hive.compactor.initiator.on = true;
SET hive.compactor.worker.threads = 1;
99. What is the purpose of the Hive metastore database?
The Hive metastore database (usually MySQL or PostgreSQL) stores metadata about Hive tables, such as their schema, location, partitioning information, and statistics. This allows multiple Hive instances to share the same metadata.
100. How do you backup and restore Hive metadata?
To backup Hive metadata, you need to backup the metastore database. The process depends on the database used (e.g., mysqldump for MySQL). To restore, you would restore the database backup and ensure the HDFS data locations are intact.
