This guide provides a curated list of common Apache Impala interview questions to help you prepare for your next Data Engineer or Big Data Developer role. Master these concepts to demonstrate your expertise in high-performance interactive SQL on Hadoop.
Last Updated: Aug 31, 2025
Table of Contents
- Core Concepts & Architecture (1-15)
- Impala SQL: DDL & Table Management (16-25)
- Impala SQL: DML & Querying (26-35)
- Query Execution & Internals (36-50)
- Performance Tuning: Statistics & Planning (51-60)
- Performance Tuning: Resource Management & Optimization (61-70)
- Data Storage & File Formats (71-80)
- Security & Integration (81-90)
- Advanced Topics & Scenarios (91-100)
Core Concepts & Architecture
1. What is Apache Impala?
Apache Impala is an open-source, native analytic database for Apache Hadoop. It's a massively parallel processing (MPP) SQL query engine that allows for high-performance, low-latency queries on data stored in HDFS, Apache Hudi, Apache Kudu, and Amazon S3 without requiring data movement or transformation. You can learn more from the official Impala website.
2. How is Impala different from Hive?
- Execution Engine: Impala has its own MPP execution engine, while Hive translates queries into MapReduce or Tez jobs. This makes Impala significantly faster for interactive queries.
- Latency: Impala is designed for low-latency, real-time queries. Hive is designed for high-throughput, batch-oriented workloads.
- Schema: Both use the Hive Metastore to share metadata, but Impala has its own catalog service to broadcast changes more quickly.
3. Explain the architecture of Impala.
Impala's architecture consists of three main components:
- Impala Daemon (impalad): Runs on each DataNode of the cluster. It accepts queries, plans and coordinates their execution across the cluster, and returns results.
- Impala Statestore (statestored): Checks on the health of all Impala daemons and continuously relays this information to each daemon. If a daemon goes offline, the Statestore informs all other daemons so that future queries can avoid the failed node.
- Impala Catalog Service (catalogd): Relays metadata changes from the Hive Metastore to all Impala daemons. This avoids the need for each daemon to issue a REFRESH or INVALIDATE METADATA statement.
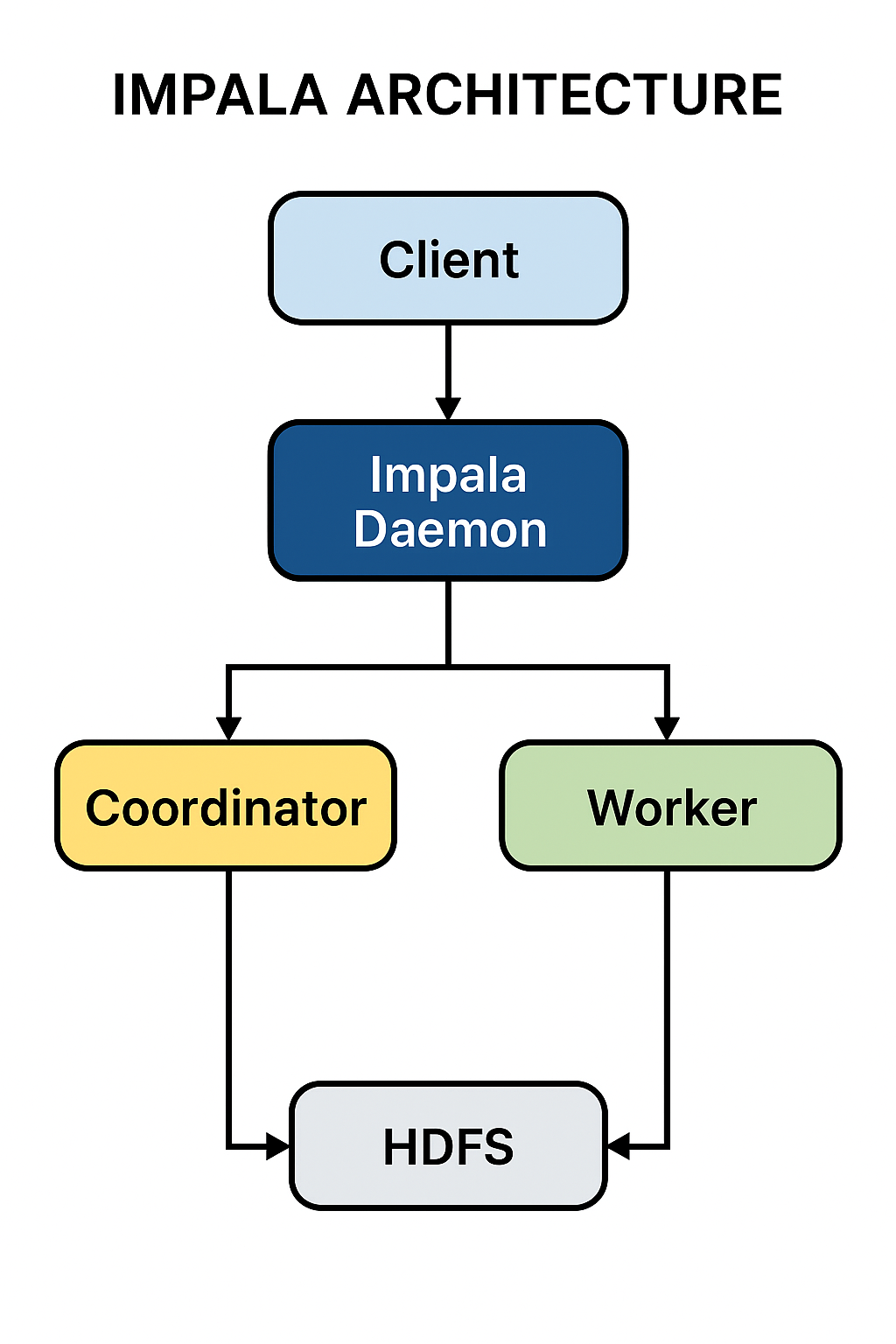
4. What are the main components of Impala?
The main components are the Impala Daemon (impalad), the Impala Statestore (statestored), and the Impala Catalog Service (catalogd). These work together with the Hive Metastore and storage systems like HDFS or S3 to execute SQL queries.
5. What is the role of the Impala Daemon (impalad)?
The Impala Daemon is the core component that runs on each node in the cluster. It accepts queries from clients, plans query execution, coordinates the query across all nodes, and returns results. Each impalad can act as both a query planner and query executor.
6. What is the role of the Impala Statestore (statestored)?
The Statestore keeps track of the health and location of all impalad daemons in the cluster. It acts as a publish-subscribe service that disseminates cluster-wide metadata to all impalad processes, helping them avoid querying failed nodes.
7. What is the role of the Impala Catalog Service (catalogd)?
The Catalog Service propagates metadata changes from the Hive Metastore to all impalad daemons. It eliminates the need for manual metadata refresh operations by automatically broadcasting metadata updates to all nodes in the cluster.
8. How does Impala integrate with the Hive Metastore?
Impala shares the same Hive Metastore as Hive, allowing both engines to access the same metadata and tables. However, Impala uses its own catalog service to quickly propagate metadata changes to all impalad daemons for better performance.
9. What is the difference between Impala and traditional MPP databases?
- Data Location: Impala queries data in place (HDFS, S3, etc.), while traditional MPP databases typically require loading data into their proprietary storage format.
- Ecosystem Integration: Impala is tightly integrated with the Hadoop ecosystem, while traditional MPP databases are often standalone systems.
- Cost: Impala is open-source and free, while many traditional MPP databases are commercial and expensive.
10. What are the key advantages of using Impala?
- High-performance, low-latency SQL queries on Hadoop data
- Familiar SQL syntax (ANSI SQL compliant)
- No data movement or transformation required
- Massively parallel processing architecture
- Integration with Hadoop security and metastore
- Support for multiple file formats
11. What are the limitations of Impala?
- Not designed for transactional workloads (OLTP)
- Limited support for UPDATE and DELETE operations
- Memory-intensive for large joins and aggregations
- No built-in fault tolerance for queries (failed queries need to be restarted)
- Less mature than some commercial MPP databases
12. How does Impala compare to Presto?
- Architecture: Both are MPP engines, but Impala is more tightly integrated with Hadoop
- Performance: Impala often has better performance for simple queries on Parquet data
- Ecosystem: Presto has broader connector support for various data sources
- Memory Management: Impala has more sophisticated memory management
13. What types of workloads is Impala best suited for?
Impala is ideal for:
- Interactive exploratory analytics
- Business intelligence and reporting
- Ad-hoc queries on large datasets
- Real-time dashboards
- ETL processing with SQL
14. How does Impala handle concurrency?
Impala handles concurrency through admission control and resource management. It can limit the number of concurrent queries and allocate resources (memory, CPU) to prevent any single query from monopolizing cluster resources.
15. What is LLVM in the context of Impala?
Impala uses LLVM (Low Level Virtual Machine) to generate optimized native code at runtime for query execution. This just-in-time (JIT) compilation significantly improves performance by reducing interpretation overhead.
Impala SQL: DDL & Table Management
16. How do you create a table in Impala?
Using the CREATE TABLE statement similar to SQL:
CREATE TABLE table_name (
column1 data_type,
column2 data_type,
...
)
STORED AS file_format
LOCATION 'hdfs_path';
17. What are the different types of tables in Impala?
- Internal (Managed) Tables: Impala manages both metadata and data
- External Tables: Impala manages only metadata, data is managed externally
- Partitioned Tables: Tables divided into partitions based on column values
- Kudu Tables: Tables stored in Apache Kudu for real-time analytics
18. How do you create an external table in Impala?
Use the EXTERNAL keyword in the CREATE TABLE statement:
CREATE EXTERNAL TABLE table_name (...)
STORED AS file_format
LOCATION 'hdfs_path';
19. What is the difference between internal and external tables in Impala?
- Internal Tables: Dropping the table deletes both metadata and data
- External Tables: Dropping the table only deletes metadata, data remains intact
20. How do you create a partitioned table in Impala?
Use the PARTITIONED BY clause:
CREATE TABLE table_name (...)
PARTITIONED BY (partition_column data_type)
STORED AS file_format;
21. How do you add a partition to a table in Impala?
Use the ALTER TABLE ADD PARTITION statement:
ALTER TABLE table_name ADD PARTITION (partition_column='value');
22. How do you view the partitions of a table in Impala?
Use the SHOW PARTITIONS statement:
SHOW PARTITIONS table_name;
23. What is the purpose of the REFRESH statement in Impala?
The REFRESH statement updates Impala's metadata for a table after data has been added or changed outside of Impala (e.g., by Hive or direct HDFS operations).
24. What is the purpose of the INVALIDATE METADATA statement in Impala?
INVALIDATE METADATA marks the metadata for a table or all tables as stale, forcing Impala to reload the metadata from the metastore on the next access. This is needed after structural changes to tables.
25. What is the difference between REFRESH and INVALIDATE METADATA?
- REFRESH: Updates metadata for a specific table after data changes
- INVALIDATE METADATA: Marks metadata as stale and reloads it on next access, used for structural changes
Impala SQL: DML & Querying
26. How do you insert data into an Impala table?
Using the INSERT statement:
INSERT INTO table_name VALUES (value1, value2, ...);
INSERT INTO table_name SELECT ... FROM another_table;
27. What is the difference between INSERT INTO and INSERT OVERWRITE?
- INSERT INTO: Appends data to the table
- INSERT OVERWRITE: Replaces the existing data in the table
28. How do you load data into Impala from HDFS?
Use the LOAD DATA statement:
LOAD DATA INPATH 'hdfs_path' INTO TABLE table_name;
29. Does Impala support UPDATE and DELETE statements?
Yes, but with limitations. Impala supports UPDATE and DELETE for Kudu tables. For HDFS tables, these operations are limited and typically require rewriting the entire data file.
30. How do you query data in Impala?
Using standard SQL SELECT statements:
SELECT column1, column2
FROM table_name
WHERE condition
GROUP BY column1
HAVING condition
ORDER BY column1
LIMIT 10;
31. What types of joins does Impala support?
Impala supports all standard SQL joins:
- INNER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- CROSS JOIN
- SEMI JOIN and ANTI JOIN (using EXISTS and NOT EXISTS)
32. How does Impala handle complex data types?
Impala supports complex data types including:
- STRUCT
- ARRAY
- MAP
- These can be queried using dot notation, array indexing, and map key access
33. What analytic functions does Impala support?
Impala supports window functions including:
- ROW_NUMBER(), RANK(), DENSE_RANK()
- LEAD(), LAG()
- FIRST_VALUE(), LAST_VALUE()
- SUM(), AVG(), COUNT() OVER windows
34. How do you handle NULL values in Impala?
Impala follows SQL standards for NULL handling:
- Use IS NULL and IS NOT NULL for comparisons
- Use COALESCE() to provide default values
- Use NULLIF() to return NULL for specific values
- Aggregate functions ignore NULL values
35. What is the difference between LIKE and REGEXP in Impala?
- LIKE: Simple pattern matching with % and _ wildcards
- REGEXP: Regular expression matching for more complex patterns
Query Execution & Internals
36. How does Impala execute a query?
Impala executes queries in these stages:
- Query parsing and analysis
- Query planning and optimization
- Parallel execution across all nodes
- Result assembly and return to client
37. What is the role of the query planner in Impala?
The query planner parses SQL statements, validates them, and creates an optimized execution plan. It determines the most efficient way to execute the query across the cluster.
38. What is the role of the query coordinator in Impala?
The query coordinator (usually the impalad that received the query) manages query execution across all nodes, collects intermediate results, and assembles the final result set.
39. How does Impala achieve parallel execution?
Impala uses massively parallel processing by:
- Dividing data into blocks distributed across nodes
- Executing query fragments in parallel on all nodes
- Using specialized operations for joins, aggregations, and sorts
- Pipelining data between operations to minimize disk I/O
40. What is code generation in Impala?
Code generation is a technique where Impala generates specialized machine code at runtime for specific queries using LLVM. This eliminates interpretation overhead and significantly improves performance.
41. How does Impala handle memory management?
Impala has a sophisticated memory management system that:
- Allocates memory for queries based on available resources
- Uses admission control to prevent memory exhaustion
- Spills to disk when memory limits are exceeded
- Tracks memory usage at the query and fragment level
42. What is admission control in Impala?
Admission control is a resource management feature that limits the number of concurrent queries and allocates resources (memory, CPU) to prevent cluster overload and ensure fair resource sharing.
43. How does Impala handle node failures during query execution?
Impala doesn't have built-in fault tolerance for queries. If a node fails during query execution, the query will fail and need to be restarted. However, the statestore helps prevent scheduling queries on failed nodes.
44. What is predicate pushdown in Impala?
Predicate pushdown is an optimization technique where filtering conditions are pushed down to the storage layer, reducing the amount of data that needs to be read and processed.
45. How does Impala handle data skew in joins?
Impala uses several techniques to handle data skew:
- Runtime filtering to reduce data early
- Broadcast joins for small tables
- Partitioned joins for large tables
- Memory management to handle large hash tables
46. What is the difference between broadcast and partitioned joins?
- Broadcast Join: The smaller table is broadcast to all nodes
- Partitioned Join: Both tables are partitioned across nodes
47. How does Impala decide which join strategy to use?
Impala's query planner chooses the join strategy based on:
- Table size statistics
- Available memory
- Join type and conditions
- Cluster configuration
48. What is runtime filtering in Impala?
Runtime filtering is an optimization where Impala generates filters during query execution and applies them to scan operations, reducing the amount of data processed.
49. How does Impala handle aggregations?
Impala performs aggregations in multiple stages:
- Pre-aggregation on each node
- Data exchange between nodes
- Final aggregation
50. What is the role of the query profile in Impala?
The query profile provides detailed information about query execution, including timing, memory usage, and data distribution. It's essential for performance tuning and troubleshooting.
Performance Tuning: Statistics & Planning
51. Why are statistics important in Impala?
Statistics help the query planner make informed decisions about:
- Join strategies (broadcast vs. partitioned)
- Execution plan optimization
- Resource allocation
- Data distribution and partitioning
52. How do you collect statistics in Impala?
Use the COMPUTE STATS statement:
COMPUTE STATS table_name;
53. What is the difference between COMPUTE STATS and COMPUTE INCREMENTAL STATS?
- COMPUTE STATS: Computes statistics for the entire table
- COMPUTE INCREMENTAL STATS: Computes statistics for new or changed partitions only
54. How do you view table statistics in Impala?
Use the SHOW TABLE STATS statement:
SHOW TABLE STATS table_name;
55. How do you view column statistics in Impala?
Use the SHOW COLUMN STATS statement:
SHOW COLUMN STATS table_name;
56. What information do table statistics provide?
Table statistics include:
- Number of rows
- Total size in bytes
- File format information
- Location information
57. What information do column statistics provide?
Column statistics include:
- Number of distinct values (NDV)
- Number of null values
- Maximum and minimum values
- Average size
- Max size
58. How often should you update statistics in Impala?
Statistics should be updated:
- After significant data changes (inserts, updates, deletes)
- After adding or removing partitions
- Regularly as part of ETL processes
59. What is the impact of stale statistics on query performance?
Stale statistics can lead to:
- Suboptimal join strategies
- Poor resource allocation
- Inefficient execution plans
- Longer query execution times
60. How do you automate statistics collection in Impala?
Statistics collection can be automated using:
- Scheduled scripts
- Workflow tools like Apache Oozie
- ETL process integration
- Custom automation frameworks
Performance Tuning: Resource Management & Optimization
61. What are some common Impala performance tuning techniques?
- Using appropriate file formats (Parquet)
- Partitioning and bucketing data
- Keeping statistics up to date
- Proper memory management
- Query optimization and rewriting
62. How does file format affect Impala performance?
File format significantly impacts performance:
- Parquet: Best performance due to columnar storage and compression
- ORC: Good performance, similar to Parquet
- Text formats: Lower performance due to parsing overhead
- Avro: Moderate performance with schema evolution support
63. How does partitioning improve Impala performance?
Partitioning improves performance by:
- Enabling partition pruning (skipping irrelevant partitions)
- Reducing data scanned for queries
- Improving join performance with partition-based joins
64. What is the optimal number of partitions for a table?
The optimal number depends on:
- Data size and distribution
- Query patterns
- Cluster size and resources
- Typically, aim for partitions containing 1-5GB of data
65. How does bucketing improve Impala performance?
Bucketing improves performance by:
- Enabling efficient joins on bucketed columns
- Reducing data shuffling during queries
- Improving data locality
66. What is the optimal number of buckets for a table?
The optimal number of buckets depends on:
- Cluster size and number of nodes
- Data size and distribution
- Join patterns
- Typically, aim for a number that matches or is a multiple of the number of nodes
67. How do you configure memory limits in Impala?
Memory limits can be configured using:
mem_limitquery option- Admission control settings
- Resource management configurations
68. What is spill-to-disk in Impala?
Spill-to-disk is a mechanism where Impala writes intermediate results to disk when memory limits are exceeded, allowing queries to complete instead of failing with out-of-memory errors.
69. How do you monitor Impala performance?
Impala performance can be monitored using:
- Query profiles
- Impala web UI
- Cloudera Manager
- System metrics and logs
70. What are some common query optimization techniques in Impala?
- Using appropriate join strategies
- Limiting data scanned with predicates
- Avoiding unnecessary columns in SELECT
- Using efficient data types
- Partition pruning
Data Storage & File Formats
71. What file formats does Impala support?
Impala supports several file formats:
- Parquet (recommended for best performance)
- ORC
- Avro
- Text files (CSV, TSV)
- SequenceFile
- RCFile
72. Why is Parquet the recommended format for Impala?
Parquet is recommended because:
- Columnar storage enables efficient scanning of specific columns
- High compression ratios reduce storage and I/O
- Predicate pushdown support
- Optimized for analytical workloads
73. What compression codecs does Impala support?
Impala supports various compression codecs:
- Snappy (good balance of speed and compression)
- Gzip (higher compression, slower)
- Bzip2 (highest compression, slowest)
- LZO (fast decompression)
74. How do you choose the right compression codec for Impala?
The choice depends on:
- Snappy: Good for most use cases (balance of speed and compression)
- Gzip: When storage space is more important than query speed
- Bzip2: When maximum compression is needed and speed is less critical
- LZO: When fast decompression is required
75. What is block size in Impala and how does it affect performance?
Block size affects performance by:
- Larger blocks reduce metadata overhead but may increase I/O for small scans
- Smaller blocks allow more parallel processing but increase metadata overhead
- Default HDFS block size (128MB) is generally good for Impala
76. How does Impala handle different storage systems?
Impala can query data from:
- HDFS
- Amazon S3
- Apache Kudu
- Apache Hudi
- Local filesystem (for testing)
77. What are the considerations for using S3 with Impala?
Considerations for S3 usage:
- Higher latency compared to HDFS
- Different consistency model
- Cost considerations for data transfer
- Need for proper bucket policies and permissions
78. How does Impala integrate with Apache Kudu?
Impala provides native integration with Kudu:
- Kudu tables can be created and managed through Impala
- Support for UPDATE and DELETE operations on Kudu tables
- Real-time analytics capabilities
- Combination of fast analytics and real-time updates
79. What are the advantages of using Kudu with Impala?
Advantages of Kudu integration:
- Real-time updates and deletes
- Fast analytics on frequently updated data
- Simplified architecture by reducing need for multiple storage systems
- Better performance for time-series and operational analytics
80. How do you optimize data layout for Impala performance?
Optimize data layout by:
- Using appropriate file formats (Parquet)
- Implementing partitioning and bucketing
- Compressing data appropriately
- Keeping files at optimal size (avoiding many small files)
- Co-locating related data
Security & Integration
81. What security features does Impala support?
Impala supports various security features:
- Kerberos authentication
- LDAP authentication
- SSL/TLS encryption
- Authorization with Sentry or Ranger
- Column-level and row-level security
82. How does Impala integrate with Kerberos?
Impala integrates with Kerberos for secure authentication:
- Requires proper keytab files
- Supports ticket-based authentication
- Integrates with Hadoop security framework
83. How does Impala integrate with Apache Sentry?
Impala integrates with Sentry for fine-grained authorization:
- Role-based access control
- Column-level and row-level security
- Integration with Hive Metastore
84. How does Impala integrate with Apache Ranger?
Impala integrates with Ranger for comprehensive security:
- Centralized security administration
- Fine-grained access control
- Auditing and monitoring
- Dynamic data masking
85. What encryption options does Impala support?
Impala supports encryption through:
- SSL/TLS for network encryption
- HDFS encryption for data at rest
- Transparent data encryption (TDE)
86. How does Impala integrate with other Hadoop components?
Impala integrates with:
- Hive Metastore for metadata management
- HDFS and S3 for storage
- YARN for resource management (in some deployments)
- Sentry/Ranger for security
- Kudu for real-time storage
87. How does Impala integrate with business intelligence tools?
Impala integrates with BI tools through:
- ODBC drivers
- JDBC drivers
- Native connectors for tools like Tableau, Qlik, Power BI
- REST APIs
88. What is the Impala ODBC driver?
The Impala ODBC driver allows Windows applications and BI tools to connect to Impala using the ODBC standard, enabling integration with tools like Excel, Tableau, and others.
89. What is the Impala JDBC driver?
The Impala JDBC driver allows Java applications to connect to Impala, enabling integration with custom applications, reporting tools, and data processing frameworks.
90. How does Impala support high availability?
Impala supports high availability through:
- Multiple impalad instances
- Load balancing across daemons
- Redundant statestore and catalog services
- Integration with load balancers
Advanced Topics & Scenarios
91. What is Impala's approach to fault tolerance?
Impala has limited fault tolerance:
- Queries fail if a node fails during execution
- Statestore helps avoid scheduling on failed nodes
- No automatic query retry or recovery
- Clients need to handle query failures
92. How does Impala handle concurrency limitations?
Impala handles concurrency through:
- Admission control to limit concurrent queries
- Resource management to allocate memory and CPU
- Query queuing for overload situations
- Workload management policies
93. What are some common Impala deployment patterns?
Common deployment patterns include:
- Dedicated Impala cluster for high performance
- Shared cluster with other Hadoop workloads
- Hybrid deployment with mixed workloads
- Cloud deployment on AWS, Azure, or GCP
94. How do you monitor and troubleshoot Impala performance issues?
Monitor and troubleshoot using:
- Query profiles for detailed execution information
- Impala web UI for cluster status
- System metrics (CPU, memory, I/O)
- Log files for error information
- Performance counters and metrics
95. What are some common Impala error scenarios and their solutions?
Common errors and solutions:
- Out of memory: Increase memory limits or optimize query
- Metadata stale: Refresh or invalidate metadata
- Node failures: Check cluster health and restart queries
- Performance issues: Check statistics, file formats, and query patterns
96. How does Impala handle time zones and date/time operations?
Impala handles time zones through:
- TIMESTAMP data type with time zone support
- Date/time functions with time zone parameters
- Conversion functions between time zones
- Session-level time zone settings
97. What is the future of Impala in the big data ecosystem?
The future of Impala includes:
- Continued performance improvements
- Better cloud integration
- Enhanced security features
- Improved fault tolerance
- Tighter integration with other data processing frameworks
98. How does Impala compare to cloud data warehouses like Snowflake or BigQuery?
- Impala: On-premises, integrated with Hadoop, more control
- Cloud warehouses: Managed service, easier scaling, higher cost
- Performance: Both offer high performance for different use cases
- Ecosystem: Impala integrates better with Hadoop ecosystem
99. What are some best practices for Impala administration?
Best practices include:
- Regular statistics collection
- Proper resource management
- Monitoring and alerting
- Regular maintenance and updates
- Capacity planning and scaling
100. How do you upgrade an Impala cluster?
Upgrading Impala typically involves:
- Planning and testing the upgrade
- Backing up metadata and configurations
- Rolling upgrade of daemons
- Verifying functionality after upgrade
- Monitoring performance post-upgrade
