This guide provides a curated list of common MongoDB interview questions to help you prepare for your next database or backend developer role. Master these concepts to demonstrate your expertise in NoSQL databases.
Last Updated: Aug 29, 2025
Table of Contents
Core Concepts
1. What is MongoDB?
MongoDB is a source-available, cross-platform, document-oriented NoSQL database program. It uses JSON-like documents with optional schemas (BSON) and is known for its flexibility, scalability, and performance. You can learn more from the official MongoDB website.
2. What is the difference between SQL and NoSQL databases?
- SQL Databases: Relational, use structured query language (SQL), have a predefined schema, and are vertically scalable.
- NoSQL Databases: Non-relational, have dynamic schemas for unstructured data, are horizontally scalable, and have a flexible data model.
3. What are documents and collections in MongoDB?
- A document is a single record in MongoDB, stored in BSON format (a binary representation of JSON).
- A collection is a group of MongoDB documents, which is the equivalent of a table in a relational database.
4. What is BSON?
BSON (Binary JSON) is a binary-encoded serialization of JSON-like documents. BSON extends JSON with additional data types such as Date and binary data, and is more efficient for encoding and decoding within the database.
5. What are the key features of MongoDB?
- Document-oriented storage
- Full index support
- Replication and high availability
- Auto-sharding for horizontal scaling
- Rich query language
- Aggregation framework
6. What is the purpose of the _id field in MongoDB?
The _id field is a unique identifier for each document in a collection. If you don't provide an _id field when inserting a document, MongoDB will automatically generate one as an ObjectId.
7. What data types does MongoDB support?
MongoDB supports various data types including String, Integer, Boolean, Double, Array, Object, Date, Timestamp, Binary Data, ObjectId, Null, Regular Expression, JavaScript, and more.
8. What is a namespace in MongoDB?
A namespace is the concatenation of the database name and the collection name (or index name), separated by a dot. For example, "mydb.mycollection".
9. What is a capped collection?
A capped collection is a fixed-size collection that maintains insertion order. Once the collection reaches its maximum size, it overwrites the oldest documents when new documents are inserted.
10. What is the difference between MongoDB and traditional RDBMS?
- MongoDB is schema-less, while RDBMS requires a predefined schema
- MongoDB uses documents (JSON/BSON) while RDBMS uses tables with rows and columns
- MongoDB is horizontally scalable, while RDBMS is typically vertically scalable
- MongoDB uses JavaScript for querying, while RDBMS uses SQL
CRUD Operations
11. How do you insert a document in MongoDB?
You can use the insertOne() or insertMany() methods:
db.collection.insertOne({ name: "Alice", age: 30 });
12. How do you update documents in MongoDB?
You can use updateOne(), updateMany(), or replaceOne() methods:
db.collection.updateOne({ name: "Alice" }, { $set: { age: 31 } });
13. How do you delete documents in MongoDB?
You can use deleteOne() or deleteMany() methods:
db.collection.deleteOne({ name: "Alice" });
14. How do you query documents in MongoDB?
You can use the find() method with optional query criteria:
db.collection.find({ age: { $gt: 25 } });
15. What are some common query operators in MongoDB?
- Comparison: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin
- Logical: $and, $or, $not, $nor
- Element: $exists, $type
- Evaluation: $expr, $jsonSchema, $mod, $regex, $text, $where
16. How do you sort query results in MongoDB?
You can use the sort() method:
db.collection.find().sort({ age: 1 }); // 1 for ascending, -1 for descending
17. How do you limit the number of documents returned?
You can use the limit() method:
db.collection.find().limit(10);
18. How do you skip documents in a query?
You can use the skip() method:
db.collection.find().skip(20).limit(10); // Skips first 20 documents
19. What is the difference between find() and findOne()?
find() returns a cursor to all matching documents, while findOne() returns a single document or null if no document matches the query.
20. How do you perform a text search in MongoDB?
You can use the $text operator after creating a text index:
db.collection.createIndex({ content: "text" });
db.collection.find({ $text: { $search: "mongodb tutorial" } });
Indexing
21. What is indexing in MongoDB?
Indexing is a data structure that improves the speed of data retrieval operations on a database collection. Indexes store a small portion of the collection's data in an easy-to-traverse form, which allows MongoDB to execute queries more efficiently.
22. What types of indexes does MongoDB support?
- Single Field Index
- Compound Index
- Multikey Index (for array fields)
- Text Index
- Geospatial Index
- Hashed Index
- Wildcard Index
- Clustered Index (MongoDB 5.3+)
23. How do you create an index in MongoDB?
You can use the createIndex() method:
db.collection.createIndex({ name: 1 }); // 1 for ascending, -1 for descending
24. What is a compound index?
A compound index is an index on multiple fields. The order of fields in a compound index is important as it determines how the index can be used for queries.
25. What is the default index in MongoDB?
The default index is the _id index, which is automatically created on the _id field for all collections.
26. What is index cardinality?
Index cardinality refers to how unique the values in an index are. High cardinality means many unique values, while low cardinality means few unique values.
27. What is covered query?
A covered query is a query that can be satisfied entirely using an index without needing to examine any documents. This results in faster query performance.
28. What is the index intersection?
Index intersection is when MongoDB uses multiple indexes to satisfy a query. The query optimizer can intersect indexes to fulfill queries that cannot be satisfied by a single index.
29. How do you check if a query uses an index?
You can use the explain() method:
db.collection.find({ name: "Alice" }).explain("executionStats");
30. What is the purpose of the $hint operator?
The $hint operator forces the query optimizer to use a specific index to execute a query:
db.collection.find({ name: "Alice", age: 30 }).hint({ name: 1 });
Aggregation Framework
31. What is the Aggregation Framework in MongoDB?
The Aggregation Framework is a way to process data records and return computed results. It groups values from multiple documents together and can perform a variety of operations on the grouped data to return a single result, similar to the GROUP BY clause in SQL.
32. What are the stages in the aggregation pipeline?
Common stages include:
- $match - Filters documents
- $group - Groups documents by specified identifier
- $sort - Sorts documents
- $project - Reshapes documents
- $limit - Limits the number of documents
- $skip - Skips documents
- $unwind - Deconstructs an array field
- $lookup - Performs a left outer join
33. How do you use the $group stage?
The $group stage groups documents by a specified identifier expression and applies accumulator expressions:
db.sales.aggregate([
{ $group: { _id: "$product", total: { $sum: "$amount" } } }
]);
34. What are accumulator operators in $group?
Common accumulator operators include:
- $sum - Calculates the sum
- $avg - Calculates the average
- $min - Finds the minimum value
- $max - Finds the maximum value
- $first - Returns the first value
- $last - Returns the last value
- $push - Adds values to an array
35. How do you perform joins in MongoDB?
You can use the $lookup stage to perform left outer joins between collections:
db.orders.aggregate([
{ $lookup: {
from: "customers",
localField: "customer_id",
foreignField: "_id",
as: "customer_info"
} }
]);
36. What is the $unwind stage used for?
The $unwind stage deconstructs an array field from the input documents to output a document for each element:
db.users.aggregate([
{ $unwind: "$hobbies" }
]);
37. How do you use the $project stage?
The $project stage reshapes documents by including, excluding, or adding new fields:
db.users.aggregate([
{ $project: { name: 1, email: 1, year: { $year: "$created_at" } } }
]);
38. What is the $facet stage?
The $facet stage allows you to create multi-faceted aggregations which characterize data across multiple dimensions (facets) within a single aggregation stage.
39. How do you use the $bucket stage?
The $bucket stage categorizes documents into groups called buckets based on a specified expression and bucket boundaries:
db.sales.aggregate([
{ $bucket: {
groupBy: "$price",
boundaries: [0, 100, 200, 300],
default: "Other",
output: { count: { $sum: 1 }, total: { $sum: "$price" } }
} }
]);
40. What is Map-Reduce in MongoDB?
Map-Reduce is a data processing paradigm for condensing large volumes of data into useful aggregated results. While the aggregation framework is generally preferred, Map-Reduce provides more flexibility for complex data processing.
Data Modeling
41. What are the data modeling approaches in MongoDB?
- Embedded Data Model: Stores related data in a single document
- Normalized Data Model: Stores references between documents
42. When would you use embedded documents?
Use embedded documents when:
- There is a "contains" relationship between entities
- One-to-many relationships where the "many" objects always appear with or are viewed in the context of their parent
- Data is not updated frequently
43. When would you use references between documents?
Use references when:
- There are many-to-many relationships
- Large hierarchical data sets
- When embedded documents would result in duplication of data
- When data is updated frequently
44. What are the considerations for designing a MongoDB schema?
- Application query patterns
- Data relationships
- Data lifecycle management
- Performance requirements
- Storage requirements
45. What is the principle of least cardinality?
The principle of least cardinality suggests that you should structure your data to minimize the number of documents that need to be accessed or updated for common operations.
46. What is a polymorphic pattern in data modeling?
The polymorphic pattern is used when documents in a collection have more similarities than differences, allowing them to be stored in the same collection while maintaining some unique fields.
47. What is the bucket pattern?
The bucket pattern is used to optimize storage and query performance for time-series data by grouping data points into buckets based on a time interval.
48. What is the extended reference pattern?
The extended reference pattern involves copying frequently accessed fields from a related document into the document that references it, to avoid frequent joins or lookups.
49. What is the subset pattern?
The subset pattern involves storing a subset of data from a large document in a separate collection to improve query performance for frequently accessed data.
50. What is the computed pattern?
The computed pattern involves precomputing and storing aggregated or computed values to avoid expensive computations at query time.
Replication
51. What is replication in MongoDB?
Replication is the process of synchronizing data across multiple servers to provide redundancy and high availability. MongoDB uses replica sets to implement replication.
52. What is a replica set?
A replica set is a group of MongoDB instances that maintain the same data set. A replica set contains multiple data-bearing nodes and optionally one arbiter node.
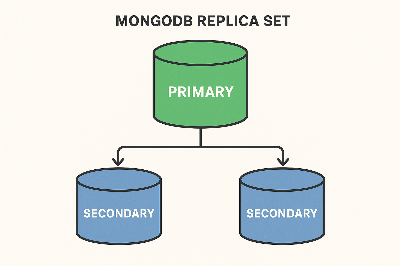
53. What are the different types of nodes in a replica set?
- Primary: Receives all write operations
- Secondary: Replicates the primary's data and can serve read operations
- Arbiter: Does not store data but participates in elections
54. What is automatic failover in MongoDB?
Automatic failover is when a replica set automatically elects a new primary if the current primary becomes unavailable. This ensures high availability of the database.
55. What is read preference in MongoDB?
Read preference allows you to control how read operations are directed to members of a replica set. Options include primary, primaryPreferred, secondary, secondaryPreferred, and nearest.
56. What is write concern in MongoDB?
Write concern describes the level of acknowledgment requested from MongoDB for write operations. It can be used to ensure that writes have been propagated to specific number of replica set members.
57. What is the oplog?
The oplog (operations log) is a special capped collection that keeps a rolling record of all operations that modify the data stored in your databases. Secondaries use the oplog to replicate operations from the primary.
58. What is a heartbeat in replica sets?
Heartbeats are periodic messages sent between members of a replica set to check their status and ensure they are reachable. If a member doesn't respond to heartbeats, it may be marked as unavailable.
59. What is the purpose of an arbiter?
An arbiter is a mongod instance that is part of a replica set but does not store data. Its purpose is to participate in elections to break ties when the replica set has an even number of members.
60. What is a rolling upgrade?
A rolling upgrade is a method of upgrading a replica set with minimal downtime by upgrading secondary members one at a time, then stepping down the primary and upgrading it last.
Performance & Optimization
71. How do you monitor MongoDB performance?
You can use:
- MongoDB's built-in database commands like db.serverStatus(), db.stats()
- MongoDB Cloud Manager or Ops Manager
- Third-party monitoring tools
- Database Profiler
72. What is the database profiler?
The database profiler collects detailed information about database operations. It can be set to different levels: 0 (off), 1 (slow operations only), or 2 (all operations).
73. How do you identify slow queries?
You can use:
- The database profiler
- explain() method to analyze query performance
- MongoDB's slow query log
74. What is covered query optimization?
A covered query is one that can be satisfied entirely using an index without needing to examine any documents. This results in faster query performance.
75. How do you optimize MongoDB memory usage?
You can:
- Ensure working set fits in RAM
- Use appropriate indexes
- Use the storage engine's cache settings
- Monitor and limit document growth
76. What is the working set?
The working set represents the total body of data that the database uses regularly. For optimal performance, the working set should fit in RAM.
77. How do you handle large collections?
You can:
- Implement sharding for horizontal scaling
- Use TTL indexes for time-series data
- Archive or delete old data
- Use appropriate data modeling patterns
78. What is connection pooling?
Connection pooling maintains a cache of database connections that can be reused, reducing the overhead of establishing new connections for each request.
79. How do you optimize write performance?
You can:
- Use bulk write operations
- Adjust write concern
- Use an appropriate storage engine
- Optimize index usage
80. What is the impact of document size on performance?
Large documents can impact performance by:
- Increasing memory usage
- Slowing down network transfer
- Increasing storage requirements
- Causing document migration if they grow
Security
81. What authentication mechanisms does MongoDB support?
MongoDB supports:
- SCRAM (Salted Challenge Response Authentication Mechanism)
- x.509 Certificate Authentication
- LDAP Proxy Authentication
- Kerberos Authentication
82. What is role-based access control (RBAC)?
RBAC is a method of regulating access to resources based on the roles of individual users. In MongoDB, you can assign users to roles that have specific privileges.
83. What are built-in roles in MongoDB?
MongoDB provides built-in roles including:
- Database User Roles (read, readWrite)
- Database Administration Roles (dbAdmin, userAdmin)
- Cluster Administration Roles (clusterAdmin, clusterManager)
- Backup and Restoration Roles (backup, restore)
84. How do you enable authentication in MongoDB?
You can enable authentication by:
- Creating user administrators
- Starting mongod with the --auth option
- Or setting security.authorization in the configuration file
85. What is transport encryption in MongoDB?
Transport encryption secures data in transit between MongoDB components using TLS/SSL. This prevents eavesdropping, tampering, and message forgery.
86. What is encryption at rest?
Encryption at rest protects data when it is stored on disk. MongoDB supports encryption at rest through:
- WiredTiger encryption (Enterprise feature)
- Filesystem or block device encryption
87. What is auditing in MongoDB?
Auditing allows you to track and log system activity for security compliance. The Enterprise version of MongoDB includes an auditing capability that can record events like authentication, authorization, and DDL operations.
88. How do you secure a MongoDB deployment?
You can:
- Enable authentication
- Configure role-based access control
- Enable transport encryption
- Enable encryption at rest
- Configure firewalls and network security
- Keep MongoDB updated
89. What is the purpose of keyfiles in replica sets?
Keyfiles contain a shared secret that members of a replica set use to authenticate to each other. All members of the replica set must have the same keyfile.
90. What are field-level redaction?
Field-level redaction is the process of removing or masking sensitive data from query results based on user privileges. This can be implemented using the $redact aggregation stage or application-level logic.
Ecosystem & Mongoose
91. What is Mongoose?
Mongoose is an Object Data Modeling (ODM) library for MongoDB and Node.js. It provides a straight-forward, schema-based solution to model application data and includes built-in type casting, validation, query building, and business logic hooks.
92. What are the advantages of using Mongoose?
- Schema enforcement
- Data validation
- Middleware (pre and post hooks)
- Population (similar to joins)
- Business logic methods
- Type casting
93. How do you define a schema in Mongoose?
You can define a schema using the mongoose.Schema constructor:
const userSchema = new mongoose.Schema({
name: String,
email: { type: String, required: true },
age: { type: Number, min: 0 }
});
94. What are middleware functions in Mongoose?
Middleware functions (also called pre and post hooks) are functions which are passed control during execution of asynchronous functions. They can be used for data validation, logging, or other preprocessing.
95. What is population in Mongoose?
Population is the process of automatically replacing specified paths in the document with document(s) from other collection(s). It's similar to a join in relational databases.
96. What are some popular MongoDB GUI tools?
- MongoDB Compass (official GUI)
- Studio 3T
- NoSQLBooster
- Robo 3T
97. What is MongoDB Atlas?
MongoDB Atlas is a fully-managed cloud database service for MongoDB. It handles deployment, maintenance, and scaling of MongoDB deployments across AWS, Azure, and Google Cloud.
98. What is MongoDB Stitch?
MongoDB Stitch (now part of MongoDB Realm) is a serverless platform that makes it easy to build applications with MongoDB, providing backend services like authentication, functions, and triggers.
99. What is change streams in MongoDB?
Change streams allow applications to access real-time data changes without the complexity and risk of tailing the oplog. Applications can use change streams to subscribe to all data changes on a collection, database, or entire deployment.
100. What are some best practices for MongoDB development?
- Use appropriate data modeling patterns
- Create indexes based on query patterns
- Implement proper security measures
- Use connection pooling
- Monitor performance regularly
- Plan for scalability from the beginning
- Implement proper backup and recovery procedures
- Keep MongoDB updated
