This guide provides a curated list of common Apache Spark interview questions to help you prepare for your next Data Engineer or Big Data Developer role. Master these concepts to demonstrate your expertise in large-scale data processing.
Last Updated: Aug 29, 2025
Table of Contents
- Core Concepts & Architecture (1-10)
- RDDs: Resilient Distributed Datasets (11-25)
- DataFrames & Datasets (26-40)
- Spark SQL & Catalyst Optimizer (41-50)
- Spark Streaming & Structured Streaming (51-65)
- Performance Tuning & Optimization (66-85)
- Deployment & Monitoring (86-95)
- Ecosystem & Advanced Topics (96-100)
Core Concepts & Architecture
1. What is Apache Spark?
Apache Spark is a fast, in-memory, and general-purpose cluster-computing framework for large-scale data processing. It provides high-level APIs in Java, Scala, Python, and R, and an optimized engine that supports general execution graphs. You can learn more from the official Apache Spark website.
2. What are the key features of Spark?
- Speed: Spark can be up to 100 times faster than Hadoop MapReduce for in-memory processing and 10 times faster on disk.
- Ease of Use: It offers high-level APIs in multiple languages.
- Generality: It combines SQL, streaming, and complex analytics in one platform.
- Lazy Evaluation: Transformations are not executed until an action is called, allowing for optimization.
- Fault Tolerance: RDDs can be recomputed from their lineage in case of node failure.
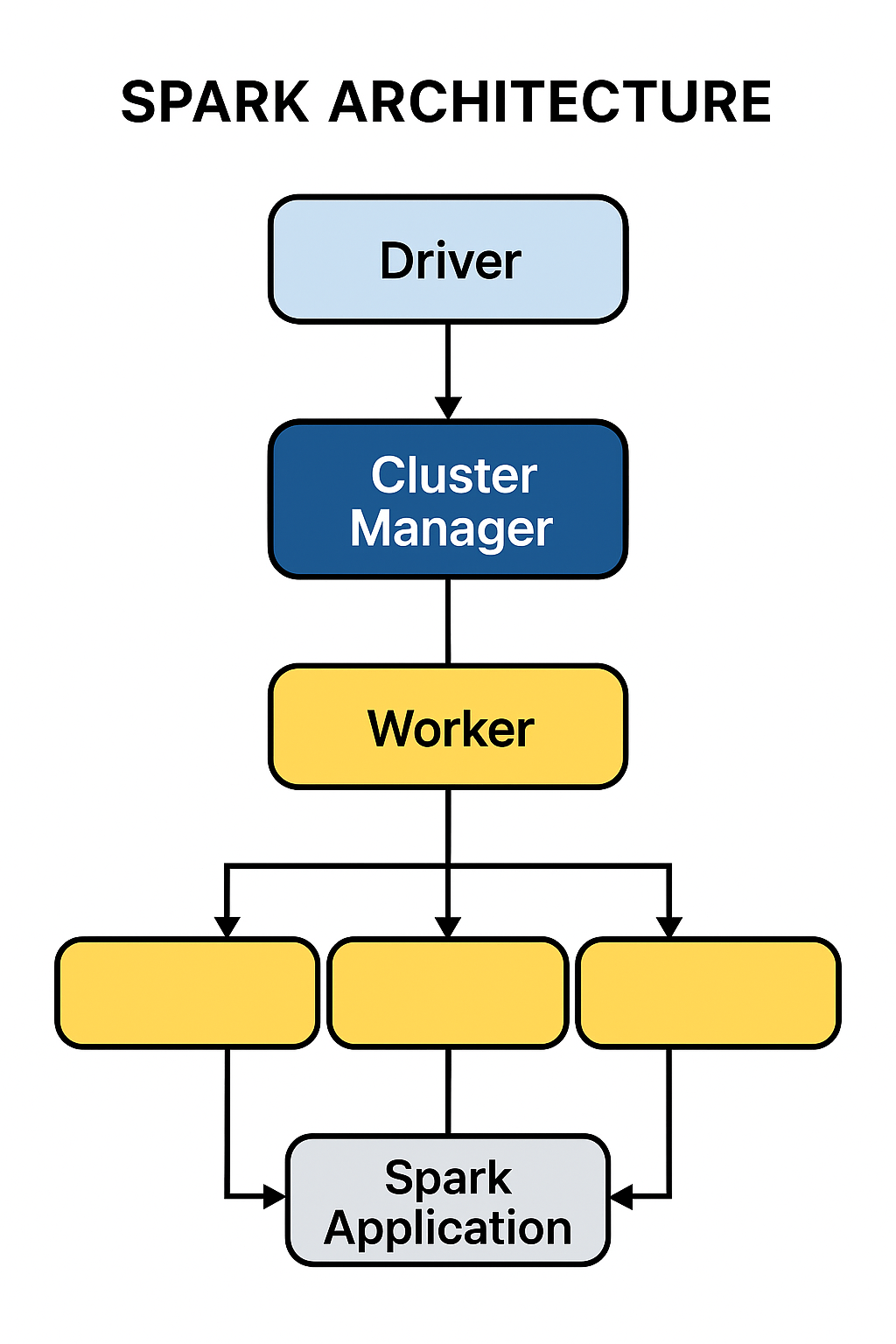
3. Explain the Spark architecture.
The Spark architecture consists of:
- Driver Program: The process running the main function of the application and creating the SparkContext.
- Cluster Manager: An external service for acquiring resources on the cluster (e.g., Standalone, YARN, Mesos).
- Executor: A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage.
4. What is the difference between Spark and Hadoop MapReduce?
- Processing: Spark performs in-memory processing, while MapReduce is disk-based, making Spark much faster.
- Ease of Use: Spark's APIs are generally easier to use than MapReduce's low-level APIs.
- Generality: Spark supports a wider range of workloads (batch, interactive, streaming, machine learning) in a single framework.
5. What is a SparkContext?
SparkContext is the entry point to any Spark functionality and represents the connection to a Spark cluster. It coordinates the execution of jobs and manages the cluster resources. In Spark 2.0+, SparkSession is the preferred entry point, which internally creates SparkContext.
6. What is a SparkSession?
SparkSession is the unified entry point for reading data and working with Spark's DataFrame and Dataset APIs. It internally contains SparkContext for RDD operations and provides a single point of entry for all Spark functionality, eliminating the need to create separate contexts for different APIs.
7. What are the different cluster managers supported by Spark?
- Standalone: Spark's built-in simple cluster manager
- Apache Mesos: A general cluster manager that can run Hadoop MapReduce and Spark applications
- Hadoop YARN: The resource manager in Hadoop 2
- Kubernetes: An open-source system for automating deployment, scaling, and management of containerized applications
8. What is a Directed Acyclic Graph (DAG) in Spark?
A DAG is a graph of the computations that Spark performs on data. It represents the sequence of transformations applied to the base RDDs. The DAG scheduler divides operators into stages of tasks based on their dependencies, which helps in optimizing the execution plan.
9. What are the different deployment modes in Spark?
- Local Mode: Runs on a single machine, useful for development and testing
- Standalone Mode: Uses Spark's built-in cluster manager
- YARN Mode: Runs on Hadoop YARN resource manager
- Mesos Mode: Runs on Apache Mesos cluster manager
- Kubernetes Mode: Runs on Kubernetes container orchestration platform
10. What is the difference between client and cluster deployment modes?
- Client Mode: The driver program runs on the client machine where the job is submitted. If the client machine crashes, the job fails.
- Cluster Mode: The driver program runs inside the cluster (on one of the worker nodes). This is more fault-tolerant as the cluster manager can restart the driver if it fails.
RDDs: Resilient Distributed Datasets
11. What is an RDD in Spark?
RDD (Resilient Distributed Dataset) is the fundamental data structure of Spark. It is an immutable distributed collection of objects that can be processed in parallel across a cluster. RDDs are fault-tolerant and can be recomputed in case of node failures.
12. What are the key properties of RDDs?
- Resilient: Can be recomputed if a partition is lost
- Distributed: Data is distributed across multiple nodes in a cluster
- Dataset: Represents a collection of partitioned data elements
- Immutable: Cannot be modified after creation (but can be transformed into new RDDs)
- Lazy evaluated: Transformations are computed only when an action is called
13. How do you create RDDs in Spark?
RDDs can be created in three ways:
- Parallelizing an existing collection in the driver program using
sc.parallelize() - Referencing a dataset in an external storage system (HDFS, HBase, etc.) using
sc.textFile() - Transforming an existing RDD to create a new RDD
14. What is the difference between transformations and actions in Spark?
- Transformations: Lazy operations that create a new RDD from an existing one (e.g., map, filter, reduceByKey)
- Actions: Operations that trigger computation and return results to the driver program or write to storage (e.g., count, collect, saveAsTextFile)
15. What is lazy evaluation in Spark?
Lazy evaluation means that Spark does not execute transformations immediately. Instead, it builds up a Directed Acyclic Graph (DAG) of transformations. The computation is only triggered when an action is called, allowing Spark to optimize the entire data processing workflow.
16. What are narrow and wide transformations?
- Narrow Transformations: Each input partition contributes to only one output partition (e.g., map, filter). No data shuffling is required.
- Wide Transformations: Each input partition contributes to multiple output partitions (e.g., groupByKey, reduceByKey). Requires data shuffling across nodes.
17. What is lineage in Spark RDDs?
Lineage is the process of reconstructing lost partitions of RDDs. Spark records the sequence of transformations used to build an RDD (its lineage graph). If a partition is lost, Spark can use this lineage to recompute just that partition from the original data.
18. What is the difference between cache() and persist()?
- cache(): Persists the RDD with the default storage level (MEMORY_ONLY)
- persist(): Allows specifying different storage levels (MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY, etc.)
19. What are the different storage levels in Spark?
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
- OFF_HEAP (experimental)
20. What is the difference between map() and flatMap()?
- map(): Applies a function to each element of the RDD and returns a new RDD of the result
- flatMap(): Similar to map, but each input item can be mapped to 0 or more output items (flattens the results)
21. What is the difference between reduceByKey() and groupByKey()?
- reduceByKey(): Combines values with the same key using a reduce function. More efficient as it performs map-side combine.
- groupByKey(): Groups values with the same key. Less efficient as it transfers all data across the network.
22. What is the difference between repartition() and coalesce()?
- repartition(): Increases or decreases the number of partitions. Always results in a full shuffle.
- coalesce(): Decreases the number of partitions. Avoids full shuffle when reducing partitions.
23. What are accumulator variables in Spark?
Accumulators are variables that can only be "added" to through an associative operation. They are used to implement counters or sums across worker nodes. Only the driver program can read the accumulator's value.
24. What are broadcast variables in Spark?
Broadcast variables allow efficient distribution of read-only values to all worker nodes. They are cached on each machine rather than being shipped with tasks, which reduces communication costs.
25. How does Spark achieve fault tolerance?
Spark achieves fault tolerance through RDD lineage. If a partition of an RDD is lost, Spark can recompute it using the lineage graph. For streaming applications, Spark uses write-ahead logs and checkpointing to ensure fault tolerance.
DataFrames & Datasets
26. What is a DataFrame in Spark?
A DataFrame is a distributed collection of data organized into named columns, similar to a table in a relational database. It provides a domain-specific language for distributed data manipulation and is optimized by Spark's Catalyst optimizer.
27. What is a Dataset in Spark?
A Dataset is a strongly-typed, immutable collection of objects that are mapped to a relational schema. It provides the benefits of RDDs (strong typing, lambda functions) with the optimization benefits of the Catalyst optimizer.
28. What is the difference between RDD, DataFrame, and Dataset?
- RDD: Low-level API, untyped, no optimization
- DataFrame: Higher-level API, untyped (Row objects), optimized by Catalyst
- Dataset: Higher-level API, strongly typed, optimized by Catalyst
29. How do you create a DataFrame in Spark?
DataFrames can be created from:
- Existing RDDs
- Structured data files (JSON, Parquet, CSV, etc.)
- Hive tables
- External databases
- Spark DataSources
30. What are the advantages of DataFrames over RDDs?
- Optimization through Catalyst optimizer
- Easier to use API with SQL-like operations
- Better performance for most operations
- Integration with various data sources
- Schema inference
31. What is the Catalyst optimizer?
Catalyst is Spark SQL's query optimization framework. It performs various transformations on logical plans, including:
- Analysis (resolving references)
- Logical optimization
- Physical planning
- Code generation
32. What is Tungsten in Spark?
Tungsten is Spark's project for improving performance by optimizing memory and CPU usage. It includes:
- Off-heap memory management
- Cache-aware computation
- Code generation
33. How do you handle missing or bad data in DataFrames?
Spark provides several methods for handling missing data:
na.drop()- Remove rows with null valuesna.fill()- Replace null values with specified valuesna.replace()- Replace specific values
34. What are UDFs in Spark SQL?
UDFs (User-Defined Functions) allow users to define custom functions that can be used in DataFrame/SQL operations. They can be registered and used in Spark SQL queries.
35. What is the difference between select() and withColumn()?
- select(): Returns a new DataFrame with the selected columns
- withColumn(): Returns a new DataFrame by adding a new column or replacing an existing column with the same name
36. How do you perform joins in Spark DataFrames?
Spark supports various types of joins:
- Inner join
- Outer join (left, right, full)
- Cross join
- Semi join
- Anti join
37. What is window functions in Spark?
Window functions perform calculations across a set of table rows that are somehow related to the current row. They are useful for operations like ranking, moving averages, and cumulative sums.
38. What is the difference between orderBy() and sort()?
Both orderBy() and sort() are used to sort DataFrames and are functionally equivalent. orderBy() is the alias for sort().
39. How do you handle schema evolution in Spark?
Schema evolution can be handled using:
- MergeSchema option when reading Parquet files
- Explicit schema definition
- Using
unionByName()withallowMissingColumnsparameter
40. What are the different ways to write DataFrames to output?
DataFrames can be written to various formats:
- Parquet
- JSON
- CSV
- ORC
- JDBC databases
- Hive tables
Spark SQL & Catalyst Optimizer
41. What is Spark SQL?
Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as a distributed SQL query engine.
42. How do you register a DataFrame as a temporary table?
Using createOrReplaceTempView() method:
df.createOrReplaceTempView("my_table")
43. What are the components of Catalyst optimizer?
Catalyst optimizer consists of:
- Parser
- Analyzer
- Optimizer
- Planner
44. What is the difference between Spark SQL and Hive?
- Spark SQL: In-memory processing, faster for iterative algorithms, supports DataFrames/Datasets
- Hive: Disk-based processing, better for very large batch processing, uses MapReduce
45. How do you enable Hive support in Spark?
By creating a SparkSession with Hive support:
SparkSession.builder().appName("app").enableHiveSupport().getOrCreate()
46. What are the different join strategies in Spark SQL?
- Broadcast Hash Join
- Shuffle Hash Join
- Sort Merge Join
- Broadcast Nested Loop Join
- Cartesian Product Join
47. How does Spark decide which join strategy to use?
Spark uses statistics and heuristics to choose the optimal join strategy based on:
- Size of the datasets
- Join type
- Available memory
- Presence of broadcast hints
48. What is the benefit of using Parquet format with Spark?
- Columnar storage format
- Efficient compression
- Predicate pushdown
- Schema evolution support
49. What is predicate pushdown?
Predicate pushdown is an optimization technique where filtering is pushed down to the data source level, reducing the amount of data that needs to be read and processed.
50. How do you optimize Spark SQL queries?
- Use appropriate join strategies
- Enable adaptive query execution (AQE)
- Use broadcast joins for small tables
- Partition data appropriately
- Use columnar formats like Parquet
Spark Streaming & Structured Streaming
51. What is Spark Streaming?
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
52. What is the difference between batch processing and stream processing?
- Batch Processing: Processes data in large chunks at scheduled intervals
- Stream Processing: Processes data in real-time as it arrives
53. What is a DStream?
DStream (Discretized Stream) is the basic abstraction in Spark Streaming. It represents a continuous stream of data, which is internally divided into a series of RDDs (micro-batches).
54. What is Structured Streaming?
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. It provides a higher-level API compared to DStreams and supports event-time processing and late data handling.
55. What are the different output modes in Structured Streaming?
- Append: Only new rows are written to the sink
- Complete: The entire updated result is written to the sink
- Update: Only updated rows are written to the sink
56. What is checkpointing in Spark Streaming?
Checkpointing is the process of saving the state of a streaming application to reliable storage. It allows the application to recover from failures and continue processing from where it left off.
57. What is watermarking in Structured Streaming?
Watermarking is a feature that allows Spark to handle late-arriving data by specifying how long to wait for late data. Data arriving after the watermark is considered too late and is dropped.
58. What are the different types of window operations in streaming?
- Tumbling windows: Fixed-size, non-overlapping windows
- Sliding windows: Fixed-size, overlapping windows
- Session windows: Variable-sized windows based on periods of activity
59. How does Spark Streaming achieve fault tolerance?
Spark Streaming achieves fault tolerance through:
- Checkpointing of metadata and data
- Write-ahead logs
- Receiver reliability
- RDD lineage for recomputation
60. What is backpressure in Spark Streaming?
Backpressure is a mechanism that automatically adjusts the receiving rate when the processing rate cannot keep up with the ingestion rate, preventing resource exhaustion.
61. What are the different streaming sources supported by Spark?
- Kafka
- File streams
- Socket streams
- Amazon Kinesis
62. What is the difference between receiver-based and direct approach in Kafka integration?
- Receiver-based: Uses Kafka high-level consumer API, may lose data without WAL
- Direct approach: Uses Kafka simple consumer API, provides exactly-once semantics
63. How do you achieve exactly-once semantics in Spark Streaming?
Exactly-once semantics can be achieved by:
- Using the direct approach with Kafka
- Using idempotent sinks
- Implementing transactional writes
64. What is the difference between mapWithState and updateStateByKey?
- updateStateByKey: Processes all keys in each batch, can be inefficient for large state
- mapWithState: Only processes keys that have new data, more efficient for large state
65. How do you monitor Spark Streaming applications?
Spark Streaming applications can be monitored using:
- Spark UI (Streaming tab)
- Custom metrics using Dropwizard
- Third-party monitoring tools
- Logging and alerting
Performance Tuning & Optimization
66. What are some common performance issues in Spark applications?
- Data skew
- Excessive shuffling
- Insufficient memory
- Improper partitioning
- Garbage collection overhead
67. How do you handle data skew in Spark?
- Use salting technique to distribute skewed keys
- Increase shuffle partitions
- Use broadcast joins for small tables
- Implement custom partitioning
68. What is the significance of partitioning in Spark?
Proper partitioning ensures:
- Even distribution of data
- Parallel processing
- Reduced shuffling
- Better resource utilization
69. How do you choose the right number of partitions?
The number of partitions should be:
- At least 2-3 times the number of cores in the cluster
- Large enough to keep all executors busy
- Not too large to avoid excessive overhead
- Typically between 100-1000 partitions for most workloads
70. What is adaptive query execution (AQE) in Spark?
AQE is a feature that reoptimizes and adjusts query plans based on runtime statistics. It can:
- Dynamically coalesce shuffle partitions
- Switch join strategies at runtime
- Optimize skew joins
71. How do you optimize shuffling in Spark?
- Minimize data to be shuffled
- Use appropriate partitioning
- Use broadcast joins when possible
- Enable AQE
- Use efficient serialization formats
72. What is the role of serialization in Spark performance?
Serialization affects:
- Network transfer speed
- Memory usage
- Disk I/O performance
Kryo serialization is generally faster than Java serialization.
73. How do you reduce garbage collection overhead in Spark?
- Use off-heap memory
- Use efficient data structures
- Cache data in serialized form
- Tune JVM garbage collection parameters
74. What is dynamic allocation in Spark?
Dynamic allocation allows Spark to dynamically scale the number of executors based on the workload. It can:
- Add executors when there are backlogged tasks
- Remove executors when they are idle
- Improve cluster utilization
75. How do you handle memory issues in Spark?
- Increase executor memory
- Adjust memory fractions (storage, execution, etc.)
- Use off-heap memory
- Cache data in serialized form
- Use smaller data types
76. What is the significance of data locality in Spark?
Data locality refers to processing data where it is stored. Spark tries to schedule tasks close to the data to minimize network transfer. Levels of locality include:
- PROCESS_LOCAL
- NODE_LOCAL
- RACK_LOCAL
- ANY
77. How do you optimize joins in Spark?
- Use broadcast joins for small tables
- Ensure tables are properly partitioned
- Filter data before joining
- Use appropriate join strategies
78. What is the benefit of using columnar formats like Parquet?
- Better compression
- Predicate pushdown
- Reduced I/O
- Schema evolution support
79. How do you handle large broadcasts in Spark?
- Compress broadcast data
- Use efficient serialization
- Consider alternative approaches if data is too large
80. What is the significance of the spark.sql.adaptive.enabled configuration?
When enabled, this configuration allows Spark to use adaptive query execution (AQE) to reoptimize queries at runtime based on actual execution statistics.
81. How do you optimize aggregations in Spark?
- Use reduceByKey instead of groupByKey when possible
- Use approximate algorithms for large datasets
- Enable AQE for dynamic optimization
82. What is the role of the Tungsten project in Spark performance?
Tungsten improves performance by:
- Off-heap memory management
- Cache-aware computation
- Code generation
- Efficient memory layout
83. How do you handle small file problems in Spark?
- Use coalesce() or repartition() to reduce number of files
- Use databricks' spark-optimize tool
- Configure appropriate file sizes
84. What is the significance of the spark.default.parallelism configuration?
This configuration sets the default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when no number is specified.
85. How do you monitor and tune Spark applications?
- Use Spark UI to identify bottlenecks
- Monitor executor metrics
- Use profiling tools
- Experiment with different configurations
Deployment & Monitoring
86. What are the different ways to deploy Spark applications?
- Spark Standalone cluster
- Apache Mesos
- Hadoop YARN
- Kubernetes
- Local mode (for testing)
87. What is the difference between client and cluster deployment modes?
- Client mode: Driver runs on the client machine
- Cluster mode: Driver runs inside the cluster
88. How do you configure resource allocation in Spark?
Resources can be configured using:
spark.executor.memoryspark.executor.coresspark.driver.memoryspark.driver.coresspark.executor.instances
89. What is the role of the Spark History Server?
The Spark History Server provides a web UI for completed Spark applications. It allows users to view details of completed applications after they have finished running.
90. How do you monitor Spark applications?
- Spark UI during execution
- Spark History Server for completed applications
- Cluster manager UIs (YARN, Mesos, etc.)
- Third-party monitoring tools
- Custom metrics and logging
91. What are some important Spark configuration parameters?
spark.executor.memoryspark.driver.memoryspark.sql.shuffle.partitionsspark.default.parallelismspark.serializer
92. How do you handle security in Spark clusters?
- Authentication using Kerberos
- Authorization with Apache Sentry or Ranger
- Encryption of data in transit
- Secure network communication
93. What is the significance of spark.sql.adaptive.coalescePartitions.enabled?
When enabled, this configuration allows Spark to dynamically coalesce shuffle partitions based on statistics collected during execution, which can improve performance by reducing the number of small tasks.
94. How do you debug Spark applications?
- Review Spark UI for task failures
- Check executor and driver logs
- Use debugging tools like jstack, jmap
- Add extensive logging to your code
95. What are some common issues when running Spark on YARN?
- Memory allocation issues
- Container allocation failures
- Resource manager bottlenecks
- Node manager communication problems
Ecosystem & Advanced Topics
96. What is MLlib in Spark?
MLlib is Spark's machine learning library. It provides various algorithms for classification, regression, clustering, collaborative filtering, and more, as well as tools for feature extraction, transformation, and pipeline construction.
97. What is GraphX in Spark?
GraphX is Spark's API for graphs and graph-parallel computation. It extends the Spark RDD with a Resilient Distributed Property Graph and provides various operators for graph computation.
98. What is SparkR?
SparkR is an R package that provides a light-weight frontend to use Apache Spark from R. It allows R users to leverage Spark's distributed computing capabilities.
99. What is Koalas in Spark?
Koalas is a project that provides a drop-in replacement for pandas, enabling pandas code to work on Apache Spark. It allows data scientists to use familiar pandas APIs on large datasets.
100. What are some recent advancements in Spark?
- Structured Streaming improvements
- Adaptive Query Execution (AQE)
- Dynamic Partition Pruning
- Enhanced Kubernetes support
- Delta Lake integration
